Evmos state bloat investigation
Table of contents
Open Table of contents
The current state of the chain
There is a big problem with the state of the Evmos chain, if we compare node snapshots we can quickly identify that something is wrong:
- Osmosis: 16GB
- CosmosHub: 15GB
- Injective: 23GB
- Evmos: 250GB
Evmos being a permissionless blockchain allows any user/contract to deploy new EVM contracts to the chain.
The token price being low enables cheap smart contract deployments and even cheaper storage usage.
Another problem of the chain related to the amount of information that is stored in the chain is that the state-sync process is not working because the node takes forever to make a snapshot of the data and then it is almost impossible to apply that snapshot.
Dealing with archival nodes
If we look at the size of the pruned database we can imagine that the databases that are being used for archival nodes are not in a better shape.
Currently, the database for archival nodes is using 17.5 TB of disk space, the database is so big that we can no longer use LevelDB as our database backend because the node will not be able to catch up with the chain while serving the RPC services, so we are using PebleDB that it uses more storage but at least we can keep getting blocks and providing historical data.
The adventure of doing some chain analysis
The first idea to get the current state of the network was to use the export genesis functionality and read the generated json file.
After running the export genesis command I started to encounter issues with the process. The genesis file generator goes through all the modules, saves all the data in the Go struct and then it uses the encoding/json lib to convert it to JSON format.
Taking into consideration that the database snapshot has a size of 250GB, my poor VM with 64GB of RAM ran out of memory after some minutes.
I ended up adding 200GB of swap to try to run the export genesis but that was not enough and made the process very slow because moving data from RAM to SWAP is not the fastest process.
Getting the bytes used by each contract in the EVM Module
After giving up on exporting the genesis file, I started to look into other solutions to read the chain state.
Instead of spending that much memory, I went through all the entries in the EVM module and saved the storage used by each contract.
You can read more about how to get the information in a memory-efficient way with the method described in my previous post, but in summary, I created a small go file, openend just the database for the EVM module and I was able to process each one of the entries without the need of having the complete storage in memory.
The results are in a Google Sheet
The findings were that a protocol with the name of XEN is taking 97% of the EVM storage, it was also discovered that their main contract has 650 million entries.
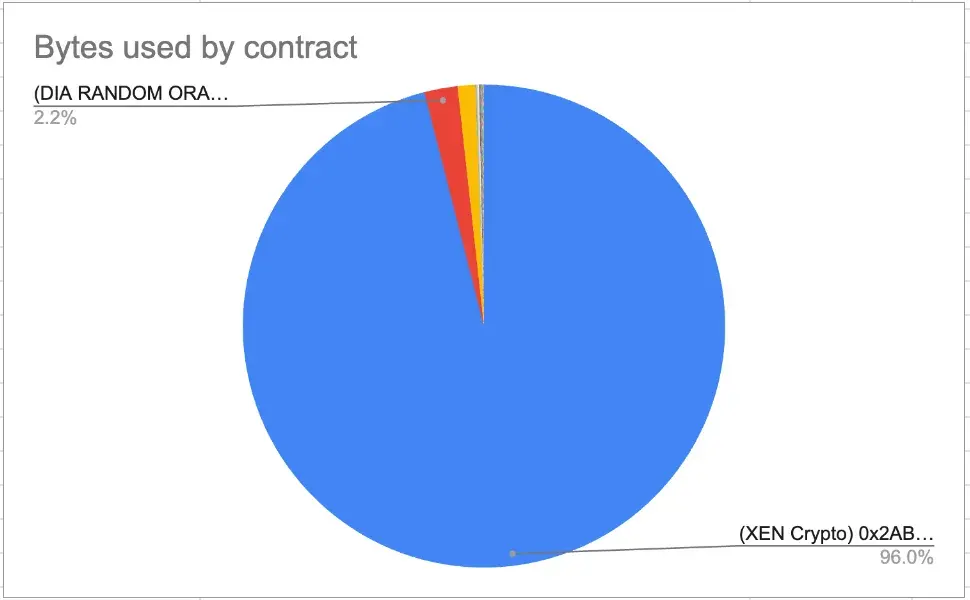
Looking for extra disk usage by the XEN protocol
Now that we discovered that the XEN protocol is the most used contract and the one that owns most of the EVM module storage, let’s see if we can find any other module where the XEN token could have impacted.
One thing that caught my eye while going through the EVM module, it’s that there are 120 million accounts in the account keeper. That does not look right for the current usage of the network.
I know that some actions by the XEN protocol create new contracts and each contract deployed using Evmos creates an entry in the account module.
Using this transaction as a starting point, I can get the byte code generated by each of the contracts deployed by the XEN token.
> eth.getCode("0x37282e677e4905e65e1506635f8ce637957da75e")
"0x363d3d373d3d3d363d739ec1c3dcf667f2035fb4cd2eb42a1566fd54d2b75af43d82803e903d91602b57fd5bf3"Now that we have the bytecode, we can iterate for all the accounts in the account module and count all the entries that match that bytecode.
It resulted in a total of 70 million accounts generated by the XEN protocol out of the 120 million accounts registered in the account keeper.
Getting the total disk usage by the protocol
The first idea was to just remove the accounts and contracts from the database using the delete functions from each module and then read the disk usage after deleting the entry.
There are a couple of issues with this approach:
- Deleting the 650 million entries from the EVM storage takes forever.
- The deleted accounts will still be in the database until the old state is pruned.
- Even if we pruned the state, we still need to rebalance the IAVL tree and compact it.
After realizing that removing the accounts would not work, I decided to go back to the idea of exporting the genesis file to get the impact of the XEN protocol.
Using the information about the 70 million accounts created by the protocol, I stored all the account numbers in a JSON file and imported them at the moment of loading the account keeper.
Then I modified the account keeper iterator to not return any of the accounts in that list, this change was enough to ignore all the accounts related to the XEN protocol.
Exporting the genesis file without the XEN protocol accounts generated a file of 36 GB
Now we need to get the usage of the XEN token for all the accounts and the storage of the EVM:
- The accounts can be exported by inverting the changes to the account keeper iterator and just exporting the auth module. This resulted in a JSON file of 13GB.
- The 70 million accounts generated by the protocol add another 5GB to the JSON file with the data they store in the EVM module.
- Getting the EVM storage for the 2 biggest contracts, the ones using 97% of the storage, was more complex because getting all the information in a Go
struct(650 million entries) and then converting it to JSON format was running out of memory even if we have more than 300GB of SWAP. Instead of creating the file, I made some estimations based on the values stored in the EVM module: 85.94 GB (biggest contract) + 1.04GB (second XEN contract): ~87 GB. We need to add around 6GB more used to encode the keys in the genesis file. So it is going to be around 93GB of data.
In conclusion, the genesis file without the XEN protocol is: 36 GB and the genesis file with the XEN protocol is 147 GB.
NOTE: the values used for the estimations are bigger than the ones in the Google Sheet. This is because the spreadsheet has the raw bytes and those values are not the ones used by the export genesis process, they do not have the correct padding.
Impact on the network
- Having 70 million more accounts in the auth module makes upgrades like Single Token Representation V2, really hard to implement. Instead of iterating using 50 million accounts, we need to go through 120 million to migrate all the balances.
- Having a contract in the EVM storage with 650 million entries makes it difficult to create snapshots for the state-sync process and it is a lot of data to apply the snapshot to restore the database.
- The snapshots for validators are huge so it increases the costs of running their infra.
- The RPC services for pruned nodes are using the same snapshots so it also increases the cost of running RPC services.
- The archival nodes are the ones suffering the most because the database increases at a rate of 1TB per month.